Recurrent Neural Networks
Introduction to Time Series
A time series is a set of observations collected over time, that spans from a starting time to an ending time , where is the total number of observations.
The key characteristic of a time series is that the observations are ordered, meaning the order in which the data points are collected is meaningful and often important for analysis.
Based on the nature of , we can distinguish between:
-
Continuous time series: Observations are continuous in time, meaning the data can be sampled always.
-
Discrete time series: A discrete sampling rate is defined (e.g., one item every second or minute), and values are sampled at regular intervals.
If the time delta between data points is fixed, the series is regularly sampled, with a sampling frequency (usually measured in hertz, Hz). The sampling frequency indicates how many observations are collected per unit of time.
➡️ We will consider discrete and regularly sampled time series!
FEATURES OF TIME SERIES
Traditional analysis approaches decompose a time series into specific elements:
- Trend: describes the long-term direction of the series, showing whether values tend to increase, decrease, or remain constant over time.
- Seasonality: regular fluctuation around the trend that occur over fixed periods (e.g., daily, monthly, yearly).
- Cycle: periodic fluctuation around the trend.
- Outliers: values that appear out-of-distribution with respect to the rest of the data.
A time series is stationary if its statistical properties — such as mean and variance — do not change over time. Conversely, if the trend is non-constant, the time series is considered non-stationary.
STL DECOMPOSITION
The STL decomposition splits data into Seasonality and Trend components using the Loess (Local regression) smoothing function**:**
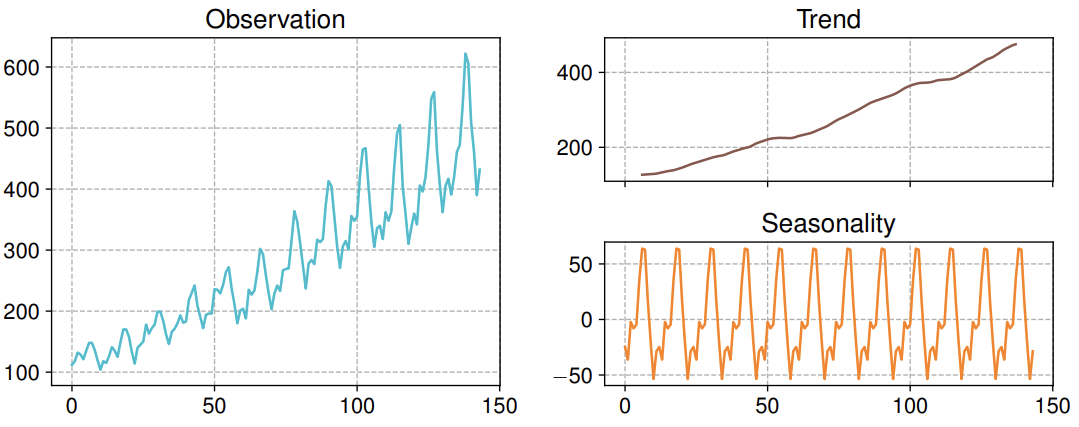
- The trend captures the long-term movement of the series.
- The seasonal component captures repeating patterns or cycles at a fixed period.
The remaining variation that cannot be attributed to trend or seasonality is called the residual or noise, representing irregular fluctuations.
Forecasting
The object is: having observed a time series over a period , we want to estimate a future value where the value is called the forecast horizon.
Ideally, if we knew the Data Generating Process (DGP) behind the series, we could predict future values perfectly. In practice, we try to learn an approximate model from the observed data.
FORECASTING PROBLEM
Most forecasting models consider a limited window of observations where is the number of past values taken into account.
The model is generally expressed as:
- represents the deterministic part of the model, which depends on past data.
- represents the stochastic part, capturing the influence of random noise or unpredictable components.
- are random disturbances with mean 0 and finite variance.
- and are the model parameters to be estimated.
This formulation shows that forecasting can be stochastic: by sampling the disturbance variables (often assumed to follow a Gaussian distribution), the model can generate multiple possible future outcomes for the same forecast horizon, rather than a single deterministic prediction.
FUNDAMENTAL APPROACHES
Forecasting models can generally be divided into two main types:
-
Autoregressive (AR) Model
Assumes that the current value of the series depends from its own past values. Formally an autoregressive model of order , denoted as , is defined as:
Here:
- Each is modeled as a linear combination of its previous observations plus a random disturbance (white noise), where the coefficients are the learnable parameters.
These past values may represent either the raw observations or intermediate representations summarizing past information.
-
Moving Average (MA) Model
Assumes that the current value depends not on past observations but on past random fluctuations (errors). A moving average model of order , denoted as , is defined as:
where
- is the empirical average of the series
- are the learnable parameters.
- represent past random fluctuations.
- are the random variations (error terms or shocks) to be estimated while learning .
- is generated as a function of the last random variations plus the average of the current series.
In this formulation, the model captures how recent deviations from the mean affect the current value. The term “moving average” comes from the fact that these deviations are computed over a sliding window, effectively modeling the residual component of the time series — i.e., the fluctuations around the trend or average level.
Data pre-processing
Before modeling, time series data must be cleaned, formatted, and transformed to make it suitable for analysis and learning.
BASIC
Pre-processing begins with data preparation, which includes:
- Extracting and formatting time information (e.g., timestamps, dates)
- Refining values by handling missing data, normalizing ranges, or removing outliers
At a higher level, transformations can be applied to represent the data in different domains:
-
Linear transforms, such as the Fourier Transform convert the series from the time domain to the frequency domain.
In this representation, the x-axis corresponds to frequency rather than time, and the y-axis indicates the amplitude of each frequency component — forming the spectrum of the time series.
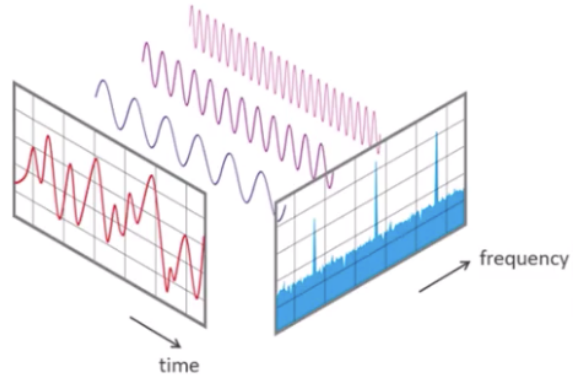
- Non-linear transforms, such as the Hilbert–Huang Transform (HHT)
CYCLICAL FEATURES
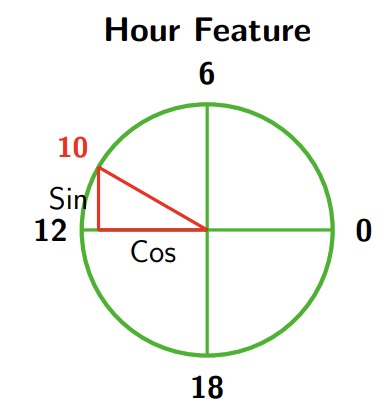
Time-related variables like hours, days, or months are cyclical — they repeat after a fixed period. To make them suitable for numerical processing (since neural networks cannot interpret raw date strings), they must be encoded numerically while preserving their periodicity.
A common and effective approach is to use sine and cosine transformations, which map cyclical variables onto the unit circle:
The same approach applies to other cyclical variables, such as months of the year. Neural networks also benefit from this encoding since their inputs become centered around zero with a fixed variance.
Recurrent Neural Networks
Recurrent Neural Networks (RNNs) are specialized architectures designed to process sequential data. Unlike traditional feedforward networks, which handle fixed-size inputs independently and have no memory of previous inputs, RNNs maintain an internal state (or “memory”) that captures information from earlier time steps. Because of these sequential dependencies, the current output depends not only on the current input but also on previous inputs.
This core feature allows RNNs to understand context and temporal dependencies, making them particularly suited for tasks involving variable-length sequences.
flowchart LR
X0[x_t-1] --> H0[h_t-1]
X1[x_t] --> H1[h_t]
X2[x_t+1] --> H2[h_t+1]
H0 --> H1
H1 --> H2
subgraph "RNN Unrolled in Time"
H0
H1
H2
end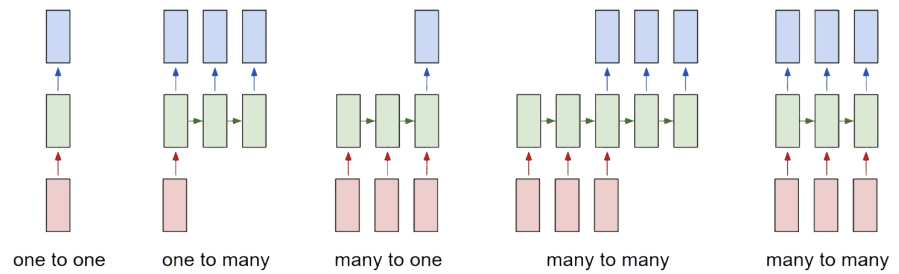
- One-to-one: the classic feedforward neural network architecture, with one input and one output.
- One-to-many: used when the input has fixed size but the output (e.g., a sequence of words) has variable length.
- Many-to-one: used in tasks like sentiment analysis, where the input is a sequence of words and the output is a single prediction (e.g., sentiment score).
- Many-to-many: used in sequence-to-sequence tasks like machine translation, where both input and output are variable-length sequences.
VANILLA RNN
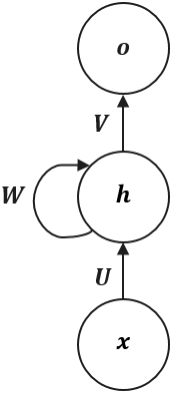
The simplest Recurrent Neural Network, often called a “Vanilla RNN”, operates using three sets of shared parameters:
- the input weight matrix, which maps inputs to the hidden state
- the recurrent weight matrix, which parametrizes hidden state transition
- the output weight matrix, which maps the current hidden state to the final output .
The behavior of the cell at each time step is defined by two simple equations:
Where:
- Hidden State Update →
- The current input (a -dimensional vector) is projected by (a matrix) into the -dimensional hidden space.
- Simultaneously, the previous hidden state (a -dimensional vector) is multiplied by the recurrent matrix (a matrix). This “feedback loop” is the core of the RNN, carrying information from the past.
- These two linear projections are summed, and an activation function (like
tanh) is applied to introduce non-linearity. The result is the new hidden state, .
- Output Calculation →
The hidden state acts as the network’s memory, providing a lossy summary of the entire input sequence up to time .
Since an arbitrarily long history is compressed into a single fixed-size vector, this summary inevitably loses some information. At any time step, the only knowledge of the past comes from , making the model effectively autoregressive of order 1 in its hidden space.
“Autoregressive of order 1” means that the current state of a system is predicted using only its immediately preceding state.
TRAINING A RNN
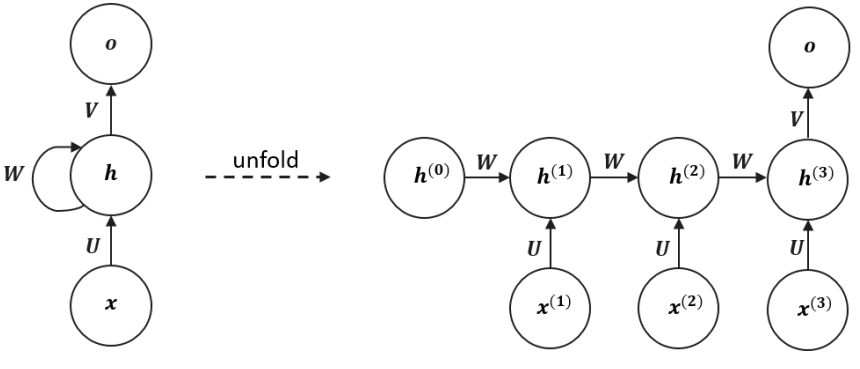
A recurrent computational graph cannot be trained directly with standard backpropagation**.** The solution is to “unfold” the network in time into a sequential computational graph with a repetitive structure.
The recurrent dynamics can be expressed as:
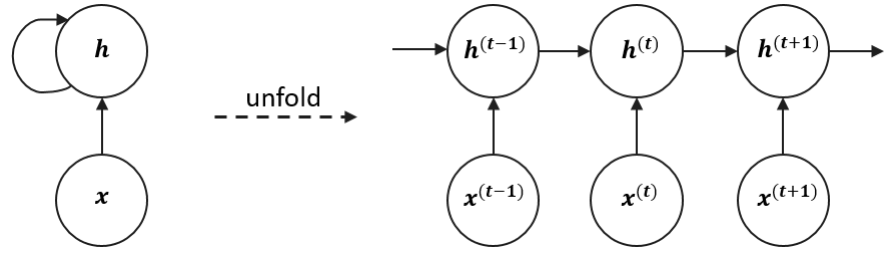
During training, the weight matrices , , and are shared across all time steps, meaning the same parameters are reused to process every input. This parameter sharing allows the RNN to handle variable-length sequences without increasing its parameter count.
BACKPROPAGATION THROUGH TIME(BPTT)
The ability to unfold a recurrent graph into a Directed Acyclic Graph (DAG) allows us to train RNNs using standard backpropagation. Since the gradient flows backward through time rather than just through layers, this process is called Backpropagation Through Time (BPTT).
Example: Processing sequences of length with an output at the end of the sequence.
Given a differentiable loss , the derivatives of the objective with respect to the weights are:
Note:
- depends only on the current state,
- while and depend on all previous sequence states.
Looking closer, we see that terms must be themselves computed through the chain rule, which results in a long product of Jacobian matrices. For example we can obtain:
Recalling that:
and temporarily ignoring the nonlinearity we can approximate:
This repeated multiplication of the same matrix can lead to two numerical instabilities:
-
Vanishing Gradient Problem
When the 2-norm of is smaller than 1, the product shrinks exponentially as the time gap increases. During backpropagation through time, gradients are multiplied by at each timestep and by the derivative of the activation function.
When both of these factors are small, it strongly pushes the total gradient toward zero. This makes it difficult for the network to learn long-term dependencies, as it’s effectively “forgetting” past information.
This problem is made much worse by “squashing” activation functions, as their derivatives are bounded:
- The sigmoid function’s derivative has a maximum value of .
- The tanh function’s derivative has a maximum value of .
-
Exploding Gradient Problem
Conversely, when the 2-norm of is greater than 1, repeated multiplication causes gradients to grow exponentially over time. This leads to unstable updates and numerical overflow, where the influence of distant steps dominates and training diverges. In this case, the model gives too much importance to the distant past and cannot properly focus on the present.
Both issues can be mitigated through:
- proper weight initialization,
- accurate choice of activation functions
- gradient clipping.
Note: these problems can also happen in deep feedforward networks; however, they are more common in recurrent architectures because these models are usually very deep (actually as deep as the length of the input sequence).
ADVANCED RECURRENT ARCHITECTURES
To overcome the problems of vanishing and exploding gradients that affect vanilla RNNs, the simple recurrent cell is replaced with a more sophisticated one that includes learnable gating mechanisms, which regulate the flow of information through time.
There are two main types of gated recurrent architectures:
-
Gated Recurrent Unit (GRU)
The GRU uses two gates to selectively update the hidden state at each time step allowing them to remember important information while discarding irrelevant details:
- Update Gate: This gate decides how much information from previous hidden state should be retained for the next time step.
- Reset Gate: This gate determines how much of the past hidden state should be forgotten.
-
Long Short-Term Memory (LSTM)
LSTMs have three gates that provide finer control over memory:
- Input Gate : Controls how much of the new “candidate state” is added to the memory.
- Forget Gate : Determines how much memory from the previous time step must be overwritten.
- Output Gate : Controls how much of the cell state is exposed to the next hidden state.
A gate in an RNN functions like a controllable switch, regulating the flow of information toward the memory cell. It’s implemented as a vector whose values range from 0 (gate completely closed), which blocks information, to 1 (gate completely open), which allows information to pass through fully.
LONG SHORT-TERM MEMORY (LSTM) NETWORKS
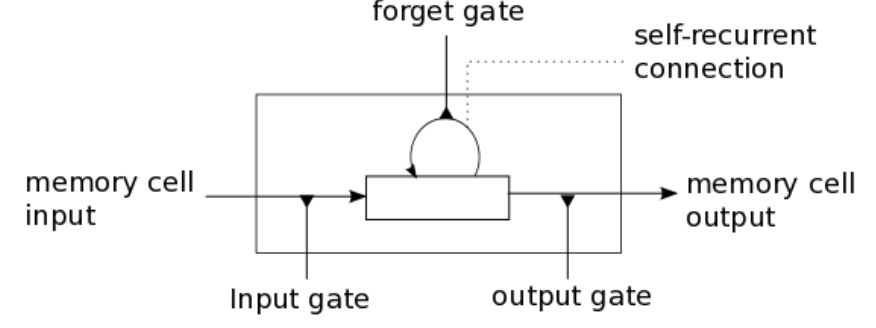
Here denotes element-wise multiplication
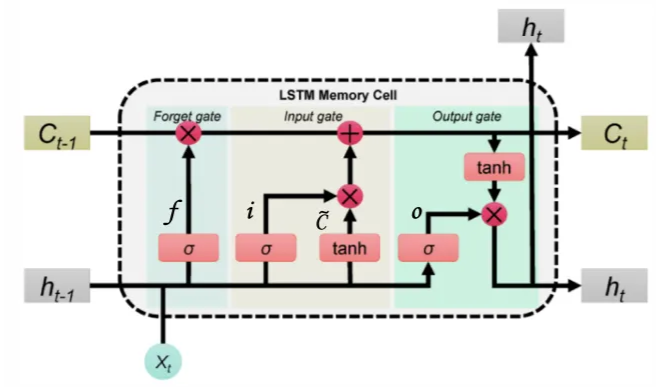
Let’s go deeper:
- Gates
Each gate is computed similarly to a standard RNN cell:
- The current input is multiplied by a weight matrix
- Summed to the previous hidden state multiplied by a weight matrix ,
- Then is passed through a sigmoid function () to produce values between 0 (“off”) and 1 (“on”).
They all have the dimention of the hidden state and as we said they all act as differentiable switches, controlling how information flows into, through, and out of the cell state, thanks to the sigmoid activation function.
-
Candidate State
This equation computes what could intuitively be described as a candidate state. Indeed, again the equation is pretty much the same as that we saw for vanilla RNN architecture. Nonetheless, the amount of influence of on the LSTM memory cell is controlled by the input gate .
-
Memory Cell’s update and hidden state
First equation computes the update for memory cell . Here:
- The forget gate controls how much of the previous memory must be kept.
- Input gate supervises the amount of newly computed state that has to flow into the memory.
Eventually, the last equation computes the output hidden state from the current memory. Here:
- Output gate regulates the amount of information to be exposed to successive layers.
Two things are passed to the next cell: and . Both are needed — is used for computing I, F, O, and , while is needed for computing .
Thus, each LSTM cell passes forward two internal states:
- The cell state represents the long-term memory of the network, and can hold past information without being overwritten quickly.
- The hidden state , which also acts as the output, represents the short-term memory; it changes frequently, reflecting the most recent processing, thus containing the information needed for the prediction of the current time step.
Key Takeaways
| Concept | Description | Main Advantage |
|---|---|---|
| Autoregressive (AR) | Predicts based on its own past values . | Simple, effective for linear dependencies. |
| Moving Average (MA) | Predicts based on past random fluctuations . | Captures shocks and residual fluctuations. |
| Vanilla RNN | Maintains a hidden state to store sequence context. | Handles variable-length inputs via parameter sharing. |
| GRU | Simplified gated RNN with Update and Reset gates. | Faster training than LSTM, mitigates vanishing gradients. |
| LSTM | Advanced gated RNN with Input, Forget, and Output gates. | Best for long-term dependencies; separates cell state from hidden state. |