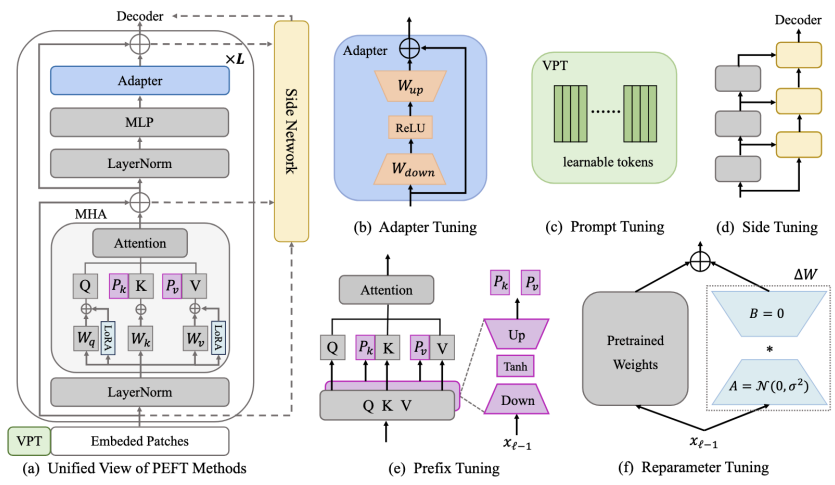
Parameter-Efficient Fine-Tuning
Introduction
FINE-TUNING LARGE LANGUAGE MODEL: CHALLENGES
Fine-tuning is essential for adapting deep learning models to unseen tasks and domain-specific datasets. This process uses pre-trained parameters as a starting point, updating them on new data to specialize the model’s existing knowledge for a specific downstream task.
In standard full fine-tuning, every parameter in the neural network is updated. However as Large Language Models (LLMs) scale to millions or billions of parameters, this approach becomes increasingly impractical due to several key factors:
- Massive Resource Demands Updating all parameters requires a huge computational power (often thousands of GPUs in parallel) and results in a high memory footprint and energy consumption.
- Redundancy because adapting a model to multiple different tasks many parameters do not actually need to change for each specific application.
- Catastrophic Forgetting: Full fine-tuning can overwrite original pre-trained knowledge. Because the process optimizes strictly for the new dataset without constraints to preserve original data performance, the model may “forget” previously learned information, leading to a loss of generalization.
Long story short. Fine-tuning large models is increasingly impractical due to their vast number of parameters and high computational costs. This paradigm is becoming inefficient and unsustainable as model sizes continue to grow.
PARAMETER-EFFICIENT FINE-TUNING
Parameter-Efficient Fine-Tuning (PEFT) techniques provide a solution by significantly reducing the resources required for fine-tuning while maintaining model performance. Instead of updating millions or billions of parameters, PEFT adapts a pre-trained model by modifying only a small subset of parameters.
Depending on how and where the model architecture is modified, several common methods are used:
- Prefix tuning: Adding learnable tokens to each layer of the model
- Adapter-based fine-tuning: Adding small, task-specific modules (adapters) into the existing model architecture.
- Reparameterization fine-tuning: Reducing the rank of the model’s weights to reduce the number of parameters
- Prompt tuning: Adding learnable tokens to the prompt.
Prompt Engineering Prompt Tuning
Unlike manual prompt engineering, where humans design text to guide behavior, prompt tuning treats the prompt as a set of parameters optimized through gradient descent.
Prompt Tuning
TRANSFORMER
Transformers serve as the foundation for modern deep neural networks, leveraging self-attention and deep contextual representations to process information.
The input to a Transformer is a prompt, which consists of a sequence of tokens (basic units such as words or subwords). These tokens are converted into embeddings, which are vector representations that condition the model’s behavior during training or inference.
Core Structure
The Transformer architecture typically consists of a stack of Transformer blocks, each containing:
- Multi-head attention
- Feed-forward layers
- Residual connections
- Layer normalization
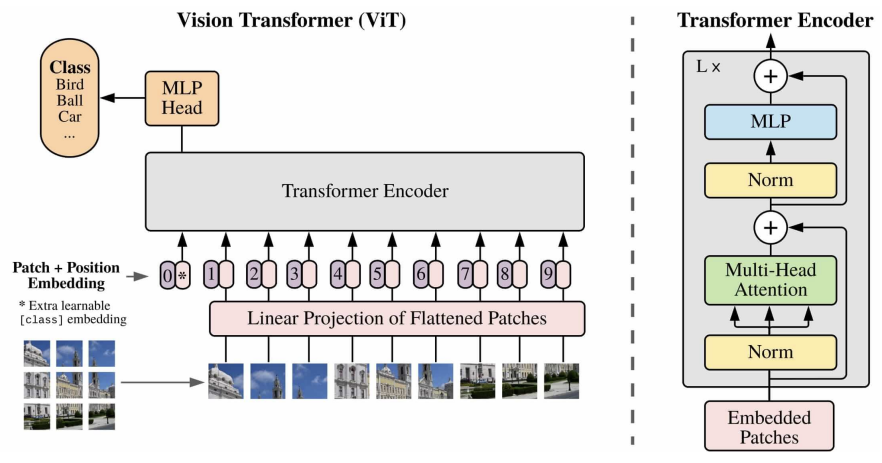
The final output representation is typically derived from a specific token or the final embedding of the sequence. This representation is then passed to a classification layer MLP to produce the end result.
PROMPT TUNING
Prompt Tuning is one of the most lightweight Parameter-Efficient Fine-Tuning (PEFT) methods. In this approach, all original model parameters, including the Transformer’s linear layers and attention projections, remain frozen.
Instead of updating the model’s internal weights, a small number of learnable tokens are added to the input prompt. During the training process, only these specific prompt tokens (and optionally the final classification layer) are updated via gradient descent.
This method is particularly effective for zero-shot and few-shot learning scenarios where labeled data is scarce. Common applications include:
- Text classification and Question Answering (QA)
- Summarization and Dialogue systems
- Multi-task learning
Visual Prompt Tuning (VPT)
Visual Prompt Tuning (VPT) is a variant of prompt tuning designed for vision models. It introduces visual prompts to adapt a pre-trained model to a new task while updating only a small number of parameters. Two variants exist:
- Shallow
- Deep
VPT SHALLOW
In the VPT Shallow configuration, a set of learnable -dimensional tokens represented as:
is added to the input prompt. They do not correspond to actual input data; instead, they are trainable parameters optimized during training.
Unlike full fine-tuning, which updates all Transformer parameters (including attention projections — query, key, value, and output — and feed-forward layers), VPT Shallow keeps all model parameters frozen except for:
- The prompt tokens
- The model Head
Procedure
- Input Preparation: Take the original input sequence.
- Prompt Prepending: Append the learnable tokens to the beginning of the sequence.
- Forward Pass: Pass the extended sequence through the frozen Transformer layers.
- Optimization: Update only the prompt tokens and, optionally, the final classification layer (Head).
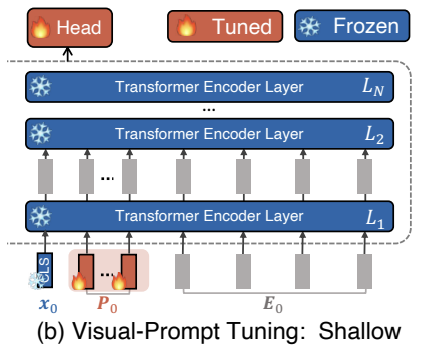
In the Shallow variant, these prompts are applied only to the first Transformer layer ():
For all subsequent layers (), the features are computed normally without additional learnable prompts:
The final output is generated by the trainable Head:
where:
- : patch embeddings
- : features computed by the -th Transformer layer
- : the CLS (classification) token
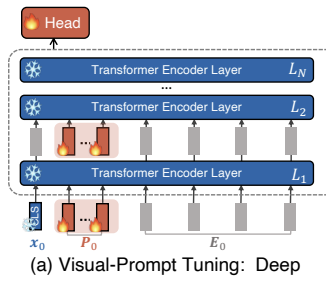
VPT DEEP
In the VPT Deep configuration, learnable prompt tokens are not only added to the input layer but are inserted into the input of every Transformer layer. These prompts are typically layer-specific, meaning each layer utilizes a unique set of trainable parameters.
In particular, for the -th layer , the collection of learnable prompts is denoted as:
The prompted model processes each layer as follows:
The final output is generated by the trainable Head:
WHY PROMPT TOKENS WORKS: THE ROLE OF ATTENTION
Although the core model weights remain frozen, prompt tokens modify the model’s behavior through the attention mechanism. Each attention layer processes both the original tokens and the learnable prompt tokens, allowing the prompts to influence how tokens attend to one another. By optimizing these prompt representations, the model can effectively modify:
- Attention weights: Changing how tokens attend to other tokens.
- Feature Importance: Determining which information is considered most relevant for the task.
- Contextual Modeling: Altering how relationships between tokens are modeled internally.
Despite minimal structural changes, the impact is significant because the prompts directly steer the model’s internal attention dynamics, without changing its core parameters.
Prefix Tuning
Prefix Tuning is a Parameter-Efficient Fine-Tuning (PEFT) method designed to adapt large pre-trained Transformers using minimal trainable parameters. It achieves this by inserting learnable parameters directly into the attention mechanism.
In a standard Transformer layer, self-attention operates on Query , Key , and Value projections:
Prefix Tuning introduces trainable key and value vectors () of length , which are concatenated to the original keys and values at every layer. The keys and values are updated as follows:
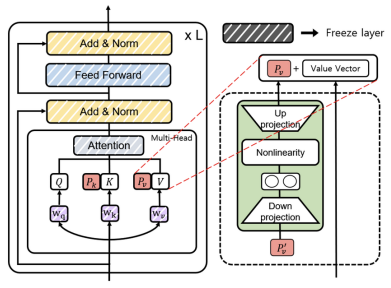
The number of output tokens remains unchanged because the output count depends on the number of queries, not the number of keys or values.
Key Characteristics
- Trainable Elements: Only the prefix vectors are learned during task-specific training. These may be static or generated dynamically by a small prefix encoder (often an MLP), which can be shared across layers or remain layer-specific.
- Frozen Components: The rest of the model—including queries, attention layers, and feed-forward blocks—remains frozen.
- Extended Context: The added key-value pairs provide extra information to the attention mechanism, encoding task-specific context and enabling the model to learn new relationships without altering original weights.
- Indirect Conditioning: The prefix vectors condition the model’s output indirectly by influencing the attention distributions.
Prompt vs Prefix Tuning: Summary of Benefits and Trade-offs
Advantages:
- Parameter-efficient: less than 1% of model parameters are trained
- No full model duplication: Suitable for multi-task and low-resource settings
- Preserve pretrained knowledge: Core transformer weights remain frozen
Prompt Tuning.
- Simplest approach: Adds trainable tokens to the input sequence
- Lightweight but limited: Operates only in the input embedding space
- Best for: Zero-shot/few-shot tasks and efficient deployments
Prefix Tuning.
- More expressive: Injects learned key/value vectors at each attention layer
- Stronger control: Can outperform prompt tuning on complex tasks
- Slightly higher overhead: Requires modifying attention internals
Adapter-based Fine-Tuning
Adapter-based fine-tuning is a PEFT approach that modifies the internal structure of a model by introducing small learnable modules (e.g., MLPs) into the layers of a pretrained model.
These modules, called adapters, enable task-specific adaptation while keeping the original model parameters frozen.
AdaptFormer
AdaptFormer is an adapter-based fine-tuning method that inserts small adapters, into the intermediate layers of large models, allowing it to adapt to new tasks while preserving the pretrained weights.
Specifically, it replaces the standard MLP block in Transformers with an AdaptMLP module, which consists of a dual-branch architecture:
- Frozen Branch (Left): The original MLP remains untouched to retain general-purpose pre-trained knowledge.
- Trainable Branch (Right): A low-rank bottleneck adapter enables efficient task adaptation.
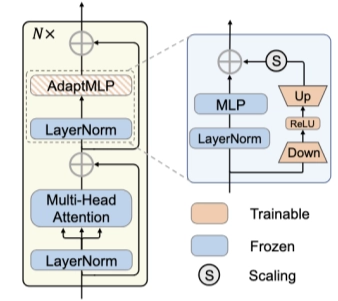
THE BOTTLENECK ARCHITECTURE
To keep the number of learnable parameters low, the adapter branch uses a bottleneck design:
- Down-Projection: The high-dimensional embedding is projected into a lower-dimensional representation.
- Activation: A non-linear activation function (ReLU) is applied.
- Up-Projection: The representation is projected back to the original dimensionality.
FORMAL REPRESENTATION
In the AdaptFormer architecture, the trainable branch processes an input feature to produce adapted features via:
where:
- and are the learnable weights of the projection layers.
- Dimensionality: represents the input feature dimension, while is the bottleneck middle dimension, where .
- Parameter Efficiency: Including biases, the total number of trainable parameters for a single adapter is .
These adapted features are then fused with the original features and the output of the frozen MLP using a residual connection:
SCALING FACTOR
The scaling factor balances pre-trained knowledge with new task-specific information. It can be treated as a hyperparameter or a learnable parameter to control how much the model deviates from its original behavior:
- : the adapter is effectively disabled; the model behaves like the original pre-trained version.
- Larger : The adapter branch contributes more strongly to the final output.
Vision tasks often require careful tuning:
- Stability: Setting generally yields better stability and performance in vision settings.
- Optimal Value: AdaptFormer achieves peak results with .
- Performance Risks: Using larger values (e.g., ) can lead to unstable or degraded performance, while values that are too small may limit effective adaptation.
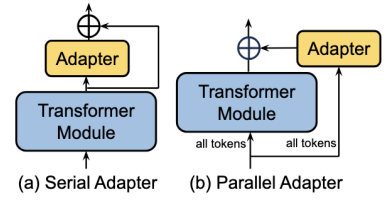
SERIAL ADAPTERS vs PARALLEL ADAPTERS
Two common adapter architectures exist:
- Parallel adapters: The adapter branch operates alongside the original layer and receives the same input as the layer it is attached to (as in AdaptFormer).
- Serial adapters: The adapter module is inserted sequentially within the computation flow, where the input to each adapter is the output of the preceding network module.
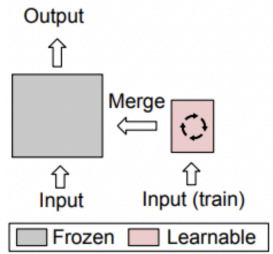
Fine-Tuning through Reparameterization
Reparameterization-based fine-tuning is a PEFT strategy where model updates are expressed through structured, low-dimensional transformations rather than direct updates to the full weight matrices. This approach reduces overfitting risks, storage costs, and computational burdens.
Core Concept
In standard fine-tuning, the original weight matrix is updated to a new matrix by adding a learned weight update :
In full fine-tuning, has the same dimensionality as , meaning every parameter is updated independently. Reparameterization methods instead express as a function of a smaller set of trainable parameters (e.g., low-rank, sparse, or generated):
The effectiveness of this approach relies on two key ideas:
- Indirect Learning: Instead of learning the weight update directly, the model learns a function that generates .
- Efficiency: The function requires far fewer parameters than the original weight matrix, making the adaptation process more efficient.
Low-Rank Adaptation
Low-Rank Adaptation (LoRA) is a reparameterization-based fine-tuning method that freezes pre-trained weights and introduces a low-rank trainable update to reduce the number of trainable parameters. While widely used in language models, LoRA is a general method applicable to any architecture, including vision models.
Mathematical Framework
For a pre-trained weight matrix , LoRA constrains the weight update by representing it as a low-rank decomposition:
where:
- and are two learnable low-dimensional matrices,
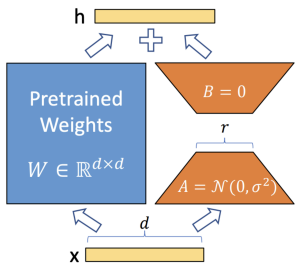
- The rank is a tunable hyperparameter (), typically set to small values like 8 or 16.
PARAMETER EFFICIENCY
LoRA drastically reduces the number of parameters required for task adaptation by shifting the learning process from the full weight matrix to the decomposition matrices:
- Original (Frozen) Parameters:
- Learnable Parameters:
By choosing a rank that is much smaller than the hidden dimensions and , the model can effectively learn task-specific approximations of the weight update while modifying only a fraction of the total parameters.
TRAINING
During the training process, the pre-trained weight matrix remains frozen and receives no gradient updates. Only the low-rank matrices and are updated.
Forward Pass Mechanism
For an input , the modified forward pass is calculated as follows:
In this operation, both and the update are multiplied by the same input . Their respective output vectors are then summed coordinate-wise to produce the final hidden representation .
This formulation reveals a structure very similar to residual adapter methods, consisting of two parallel branches:
- Frozen Branch: Computes the original output .
- Trainable Residual Branch: Computes through a bottleneck process.
INITIALIZATION
A key practical detail in LoRA is the initialization of the low-rank matrices and . To preserve the model’s pre-trained behavior at the start of training:
- Matrix is initialized as the zero matrix
- Matrix is initialized following a random Gaussian
This asymmetrical initialization ensures that the initial weight update is exactly zero (). As a result, the model initially behaves exactly like the original pre-trained model, avoiding disruptive changes during early training.
INFERENCE
The low-rank decomposition is used only during training to reduce the number of trainable parameters. During inference, it is merged into a single weight matrix:
Key Benefits for Deployment
- Zero Additional Overhead: Unlike other PEFT methods, there is no extra computational cost during inference.
- Architectural Consistency: The final model remains the same size as the original, maintaining full computational efficiency.
- No Latency Penalty: Because the branches are collapsed into one, the model processes data at the same speed as the pre-trained version.
Scale or/and Shift
SCALE AND SHIFT FINE-TUNING
Scale-and-shift methods are a class of PEFT techniques that adapt pre-trained models by applying lightweight, trainable affine transformations to internal activations.
Core Concept
The model’s behavior is adjusted by learning how to rescale and shift its internal representations. In a standard pre-trained model, an output activation from one layer is passed directly to the next. In scale-and-shift approaches, a simple transformation is inserted between layers:
where:
- is an activation from the frozen model,
- is a learnable scaling factor that modulates which features are emphasized.
- is a learnable offset or shift.
During training only the parameters and are learned, while all other model parameters remain frozen. This mechanism is conceptually similar to Layer Normalization, as it slightly modifies internal activations to align the model with a specific downstream task. By scaling and shifting these activations, the model can emphasize different features without changing the underlying weights.
BIAS-TERMS FINE-TUNING (BITFIT)
Bias-Terms Fine-Tuning (BitFit) is an extremely sparse PEFT method that updates only the bias terms of a model while keeping all weight matrices frozen.
Given an attention-based network, BitFit targets the bias components () within these operations:
- Attention projections:
- Feed-forward layers:
- Layer normalization:
During the fine-tuning process, only the bias terms are updated.
Since bias parameters represent only a small fraction of the total parameters, this method is extremely parameter-efficient. It can be interpreted as a simplified version of scale-and-shift methods: while scale-and-shift learns both a scaling factor () and an offset (), BitFit keeps the scaling factor fixed and optimizes only the shift (the bias).
INFUSED ADAPTER BY INHIBITING AND AMPLIFYING INNER ACTIVATIONS (IA)3
(IA)³ is another PEFT method designed specifically for Transformer architectures. It adapts a pre-trained model by introducing learnable scaling factors directly into the internal components of the attention mechanism.
In a standard Transformer, the self-attention mechanism is defined as:
(IA)³ modifies this process by applying learnable scaling vectors (, , and ) to the Query, Key, and Value representations via element-wise multiplication ():
Instead of concatenating additional tokens, this method modifies the attention computation by scaling the internal representations.
This approach is effective because adapting the attention mechanism often captures most of the task-specific adjustments required for the model.
SCALING & SHIFTING FEATURES (SSF)
Scaling & Shifting Features (SSF) is a PEFT technique that adapts pre-trained models by modulating activations after key architectural operations.
Specifically, SSF applies an SSF-ADA layer following Multi-Head Self-Attention (MSA), Feed-Forward Networks (FFN), and Layer Normalization.
The SSF-ADA layer modifies an activation using learnable scaling () and shifting () vectors through element-wise multiplication and addition:
Reparameterization for Inference
A significant advantage of SSF is that, since the operations are linear, the learned parameters can be merged into the original weights for inference. Given an input and the original weight and bias , the operation:
Can be reparameterized as:
Conclusions
Takeaway: PEFT provides an effective and scalable alternative to full fine-tuning, enabling the adaptation of large models with minimal overhead. It is a practical and principled solution for transfer learning and multi-task adaptation.
- Comparable performance to full fine-tuning on many tasks, with significant savings in parameters, memory, and computation.
- Modularity and reusability across tasks.
A variety of strategies exist:
- Prompt/Prefix Tuning: Input- or attention-level conditioning.
- Adapters: Small trainable modules inserted within layers.
- Reparameterization: Low-rank or structured weight updates (e.g., LoRA).
- Scale-and-Shift: Affine modulation of internal activations (e.g., BitFit, IA3).
Key Takeaways
| Concept | Description |
|---|---|
| Why PEFT | Full fine-tuning of LLMs is impractical — massive compute, redundant updates, catastrophic forgetting |
| Core idea | Freeze the pretrained weights, train only a tiny task-specific subset of parameters |
| Prompt Tuning | Prepend learnable tokens to the input; all model weights frozen, only prompts and (optional) head trained |
| VPT Shallow | Visual prompt tokens injected only at the first Transformer layer |
| VPT Deep | Layer-specific learnable prompts injected at every Transformer layer — more expressive, more parameters |
| Prefix Tuning | Inject trainable key/value vectors at every attention layer; conditions attention internals indirectly |
| Prompt vs Prefix | Prompt = input embedding space, simpler. Prefix = attention internals, stronger control on complex tasks |
| Adapters | Small bottleneck MLPs (, ) inserted into layers and trained while the backbone stays frozen |
| AdaptFormer | Parallel adapter branch alongside the frozen MLP, fused via residual: |
| Serial vs parallel adapters | Serial sits inside the data flow; parallel runs alongside the frozen layer with the same input |
| Reparameterization | Express the weight update as a function of fewer parameters: |
| LoRA | with . Init so training starts from the pretrained model |
| LoRA at inference | Merge into a single matrix — zero overhead, no latency penalty |
| BitFit | Update only the bias terms; the most extreme scale-and-shift simplification (no scale, only shift) |
| (IA)³ | Element-wise scaling vectors injected into Q/K/V — modulate attention without adding tokens |
| SSF | Affine modulation after MSA / FFN / LayerNorm; mergeable into weights for inference |
| Common trade-off | < 1% trainable parameters, comparable accuracy to full fine-tuning, modular and reusable across tasks |